Hypothesis Testing based on Rank Order
2024-11-20
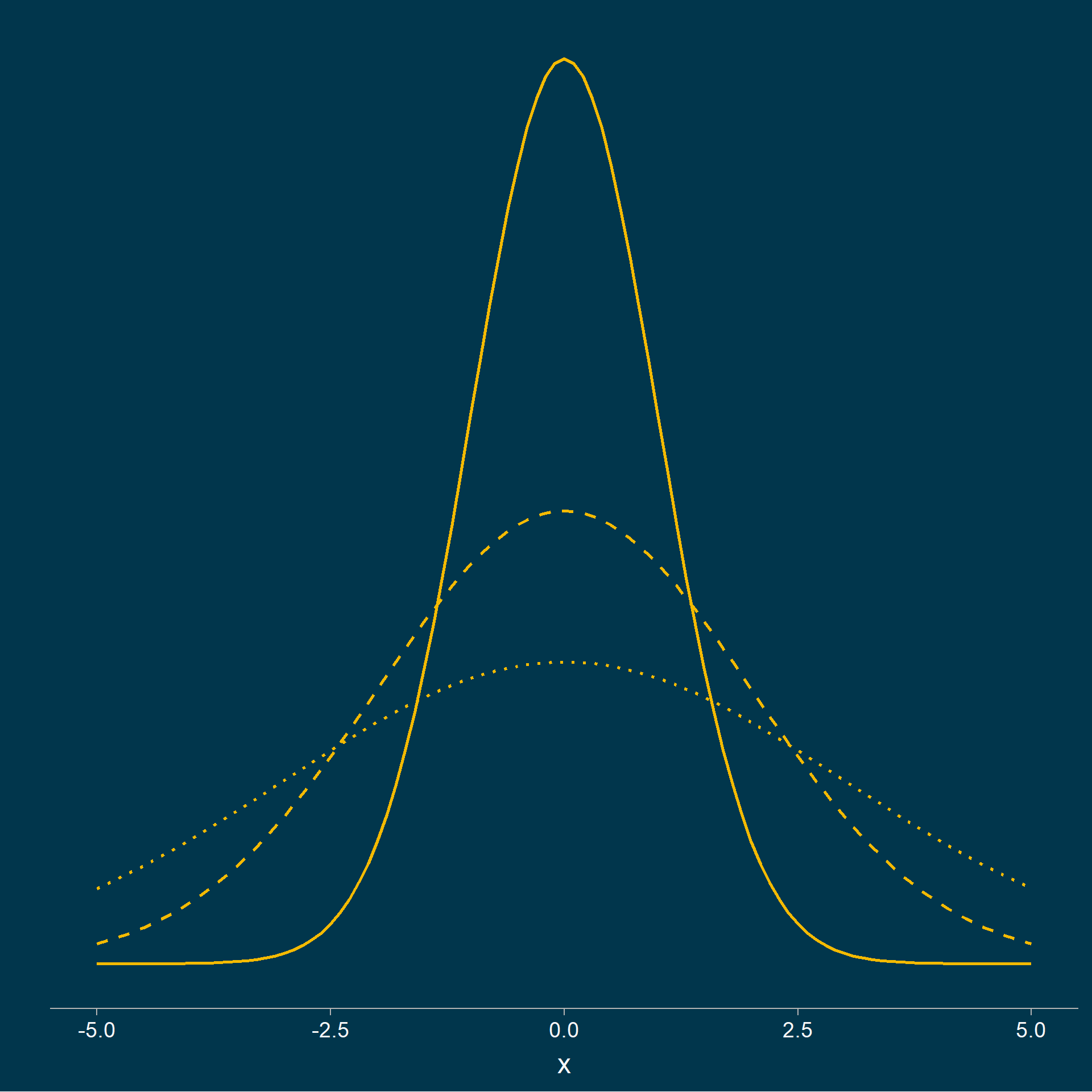
Why use ranks?
- Fewer assumptions are better
- Normality rarely holds
- When assumptions are violated, obtained p-values are wrong
Important
We lose statistical power if the data actually meet the conditions for a parametric (eg., Student’s) test

Mann-Whitney U / Wilcoxon rank-sum test
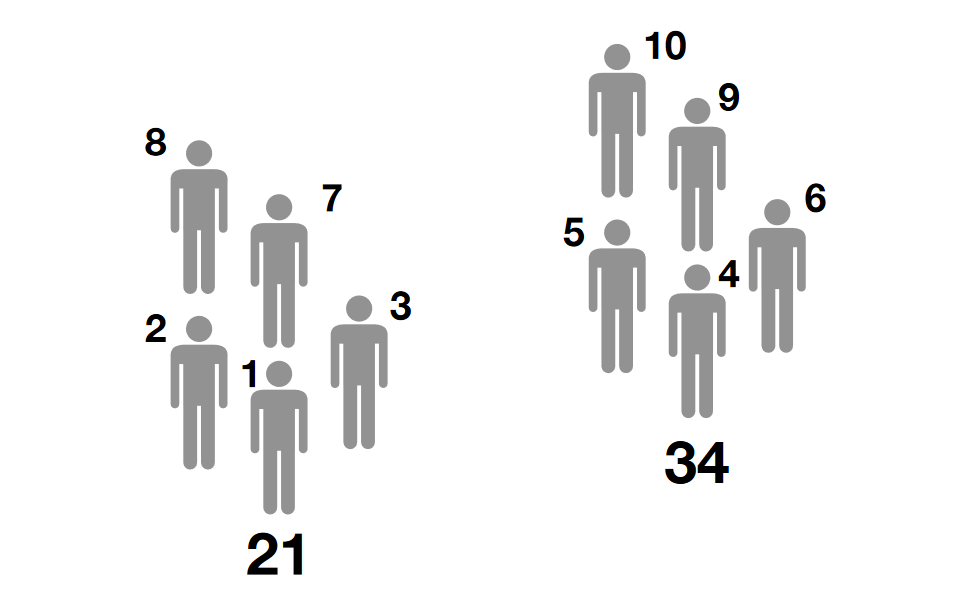
Exercise: MWW test
Examine whether people with different
altitudes of residence
differ according to the concentration of fibrinogen.

Statistical test selection
- One or two samples
- Repeated measurements or not
- Data type (numeric, ordinal, categorical)
- Use data summaries to determine whether the data meet the normality assumption
![]()